A Lazy Saturday Upgrade: Adding RAG to CLARA
CLARA could query structured data perfectly but struggled with contextual questions. Adding RAG solved this, creating a hybrid system that understands both facts and feelings.

In my previous post, I detailed how I connected my Obsidian notes to AI using MCP. While I managed to succeed, the approach had an obvious flaw: I was trying to give structure to unstructured data.
Giving structure, especially by representing my notes as a graph, meant I could find relationships and query for links. CLARA could tell you "What movies did I watch in March?" perfectly. But ask "How do I feel about work lately?" and it struggled. CLARA could still answer that, but the LLM needed to process the entirety of my vault. For queries that required understanding context rather than following connections, this solution was inefficient.
That's why I added RAG (Retrieval-Augmented Generation) to CLARA.
RAG (Retrieval-Augmented Generation) is like having a smart librarian for your notes.
Instead of reading every single book to answer your question, the librarian first finds the 3-5 books most likely to have your answer, then reads only those. RAG does the same thing: it searches through all your notes to find the most relevant ones, then uses just those few notes to answer your question. Much faster than reading everything!
Understanding Vectors
Now, let's try to understand vectors. My notes obviously contain words, and words have meaning. For example, the word 'Blue' means color to us humans. But a computer doesn't exactly know what 'Blue' means. But what it can do is assign the word 'Blue' a unique list of numbers, like [0.2, -0.5, 0.8, 0.1, ...]. This list might have hundreds of numbers.
Now this unique list represents 'Blue'. It does the same with other colors, giving them all unique lists of numbers. These lists are called vectors; hence, the database is called a vector database.
This way it creates a mapping where words with similar meanings are clustered together in number space. So 'Blue' and 'Red' (both colors) end up with lists that are mathematically close, while 'Blue' and 'Elephant' end up with very different lists.

More on RAG
RAG follows a very similar process. Instead of words, it deals with entire sentences or notes. We chunk long-form notes into bite-sized pieces and give them their own unique list of numbers.
And when I ask a question, this question also gets translated into its own list of numbers. Then RAG tries to calculate the closest chunks to my question. This means finding chunks with similar themes and meaning.
Before, CLARA had to load my entire vault for the LLM to parse through. Now, CLARA can load only the relevant chunks of text, making this more efficient.
Technical Implementation
I initially tried FAISS for the vector database, but quickly ran into a limitation. Sometimes I need to search within specific folders—like finding thoughts about work from my "Daily" folder, or looking for media notes in my "Movies" folder. FAISS couldn't handle this folder-based filtering elegantly, so I switched to Chroma, which lets me store metadata alongside vectors.
For the rest of the stack, I used RecursiveCharacterTextSplitter from LangChain for chunking and BAAI/bge-small-en-v1.5 for embeddings.
The process is straightforward: I recursively parse all my Obsidian notes, chunk them into bite-sized pieces, embed them, and add them to the database. To avoid reprocessing everything each time, I maintain a JSON file tracking which notes I've processed and their last modified timestamps. This way, I only process new notes or ones that have changed recently.
I used AI to help implement this, but it wasn't without issues. The LLM I used made a significant mistake that only processed the first file in each folder, which I had to debug and fix myself. Not only that, the implementation had a few other bugs. AI is a powerful tool that helped get my foot in the door. But I still had to know what was happening to get everything to work.
Finally, I exposed this database as a tool to LLMs using MCP—the same protocol I used for the graph database.
Real World Example
I asked Claude about my feelings on Tamil movies, and here it is, planning out its strategy.
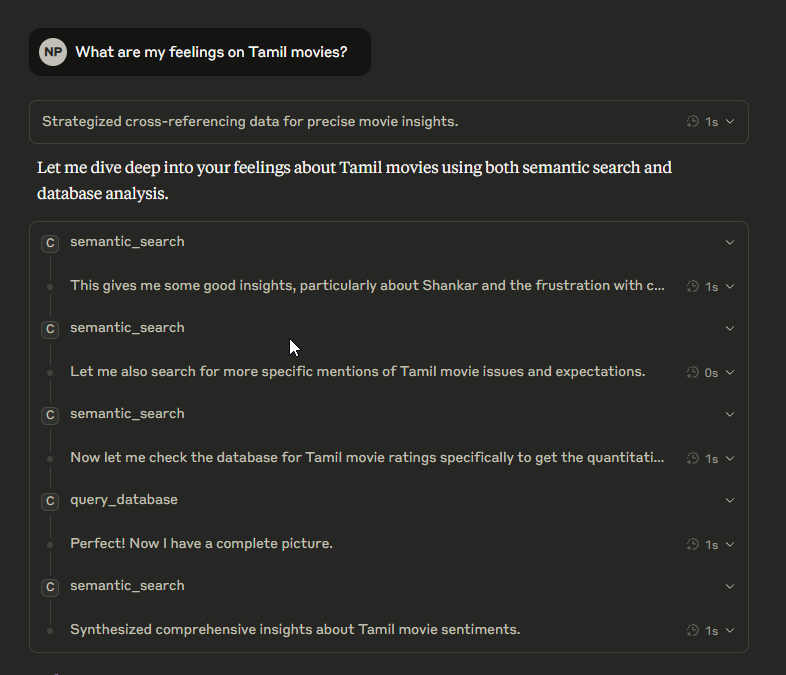
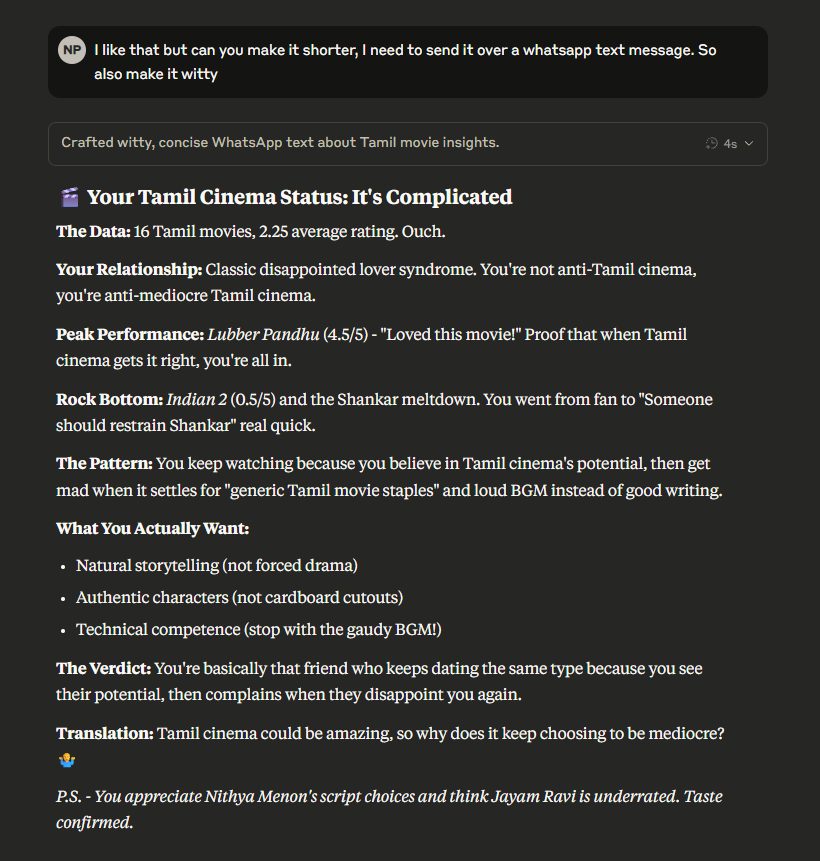
The actual response was insightful but too verbose, so I had Claude make it shorter to fit in a screenshot. And yeah, it was pretty much dead-on accurate.
Conclusion
I cobbled this entire RAG module for CLARA on a lazy Saturday based on a suggestion from a friend. It was fun, but at the same time, I believe it adds a meaningful step up to my PKM system.
Now, CLARA can handle searches for contextual meaning and structured relationships between my notes. I am working on yet another new personal project to further enhance this system.
There is still work left to do here—more experimentation, more ways to make the current system efficient. If you'd like to follow my journey, please feel free to subscribe, or if you have thoughts or suggestions, please leave a comment or reach out to me.