Building AMY — a persistent memory layer for LLMs
Amy is a MCP server that gives Claude a persistent, graph-based memory — no embeddings, no vector store, just Neo4j and local markdown files.

I got married recently, changed teams at the office, and ever since I have been busy. Busy enough that my journaling got affected. I was not writing or capturing my thoughts effectively. But I did notice that I was using LLMs to brainstorm a lot. After a session, those conversations are practically expired.
Claude and other systems can revisit old chats, but the context is lost by then. Like Claude still thinking I am learning frontend when that task ended long back. Also I have no control over what these LLMs remember. I can't go in and make changes.
So I built AMY, a MCP server that gives Claude, or any LLM, a persistent memory. Or in simpler terms, I gave LLMs a notebook. This way, I can not only capture my ideas, but build on them at a future date.
Why not RAG?
My issue with RAG is simple — similarity is not the same as relevance. A vector search finds what is semantically close, but close is not always useful. And RAG retrieves one note. What about the notes connected to that note? The context around an idea is often more valuable than the idea itself.
That's when I came across Karpathy's LLM + Obsidian idea and wanted to extend it. The concept is straightforward — maintain local markdown files and a single index.md that acts as a table of contents. Load the index into the LLM and let it decide which notes to read. The LLM becomes the retriever, not a similarity function.
In my implementation, Gemma 4 handles the indexing and retrieval decisions. Neo4j sits underneath as a knowledge graph, so when Amy recalls a note, it can also traverse the relationships around it, finding not just the note you asked for, but the ones connected to it.
Remembering and Recalling
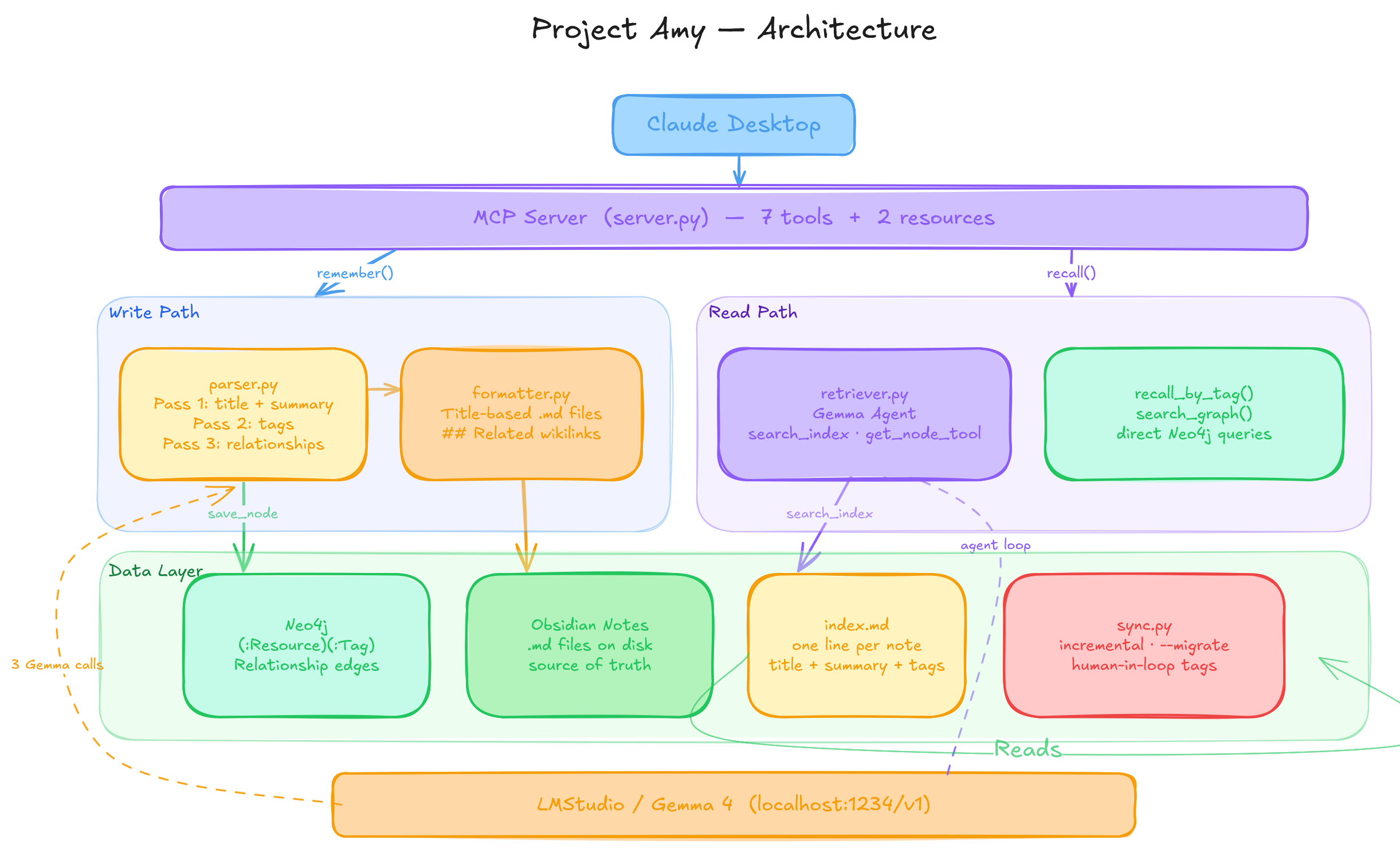
The stack is simple. I used LM Studio to expose Gemma 4 E4B over REST apis. Amy is exposed to Claude as a MCP server. Neo4J is the data layer, along with MD files. Obsidian for human in the loop interaction.
How it works - Remember and Recall
When I had my initial prototype for Amy done, I began using it. Every time I brainstorm or have a conversation that I feel needs to be captured or referenced in the future, I ask Claude to remember it. Claude summarizes the conversation and sends it over to Gemma. This is the Remember tool call.
Gemma then runs three passes on it. The first pass summarizes the note in one line for index.md. The second pass checks the tag registry to assign existing tags — or create new ones if needed. The third pass checks index.md to find which existing notes this new note can form relationships with.
At the end of the three passes, three things happen: index.md gets a new entry, a new markdown note is written to disk, and the Neo4j graph is updated with the new node and its relationships.
The final step is mine. I open Obsidian, quickly review the note, and adjust the tags if needed. That's the human-in-the-loop moment, I can see exactly what Amy stored and correct it in plain text. I have a sync script that applies my changes and keeps the index and neo4j graph updated.
Today, when I wanted to write this blog post, I asked Claude to do a search for the Amy memory system. Claude can use search, which internally calls Gemma. Gemma ranks the notes based on relevance and returns the results. Claude can then read the note in full or search connected nodes. This is the Recall tool call.
If Claude decides to do a search itself, it can load the index or the tag list and search based on tags.
In this instance, I asked Claude to go over the notes and help me create a diagram.
Conclusion
There are improvements needed, for sure. One thing I plan on doing is putting this on a home server. The eventual plan is also to ditch a closed-weight LLM and use an open-weight LLM on local hardware.
I also think ditching Neo4j for something like NetworkX might be worthwhile.
But for now, I am happy with the current state. The more I use it, the more bugs or ideas might surface. When they do, you can be sure I will be using remember and recall.
If you'd like to follow my journey, please subscribe. If you have thoughts or suggestions, feel free to leave a comment or reach out to me.