One Note at a Time: Turning Notes Into a Personal Jarvis
How I built a second brain using Obsidian, Neo4j, local notes, and the Model Context Protocol to let AI query my thoughts.

Last August, I had a bike accident. After surgery, I was stuck in bed for weeks with nothing but my thoughts and the internet for company. Those thoughts were fleeting, random, unstructured, and constantly slipping away. I hated that.
The fix? Write everything down. No filters, no expectations. Just capture it all.
That simple act pulled me into the world of PKM (Personal Knowledge Management) and eventually to Obsidian.
I was already logging the media I consumed using tools like Letterboxd and Goodreads. Obsidian gave me a way to centralise all of that. To link ideas, build connections, and turn scattered notes into something richer. That’s how I started journaling, and how I started building on the things I think about.
But I didn’t stop there.
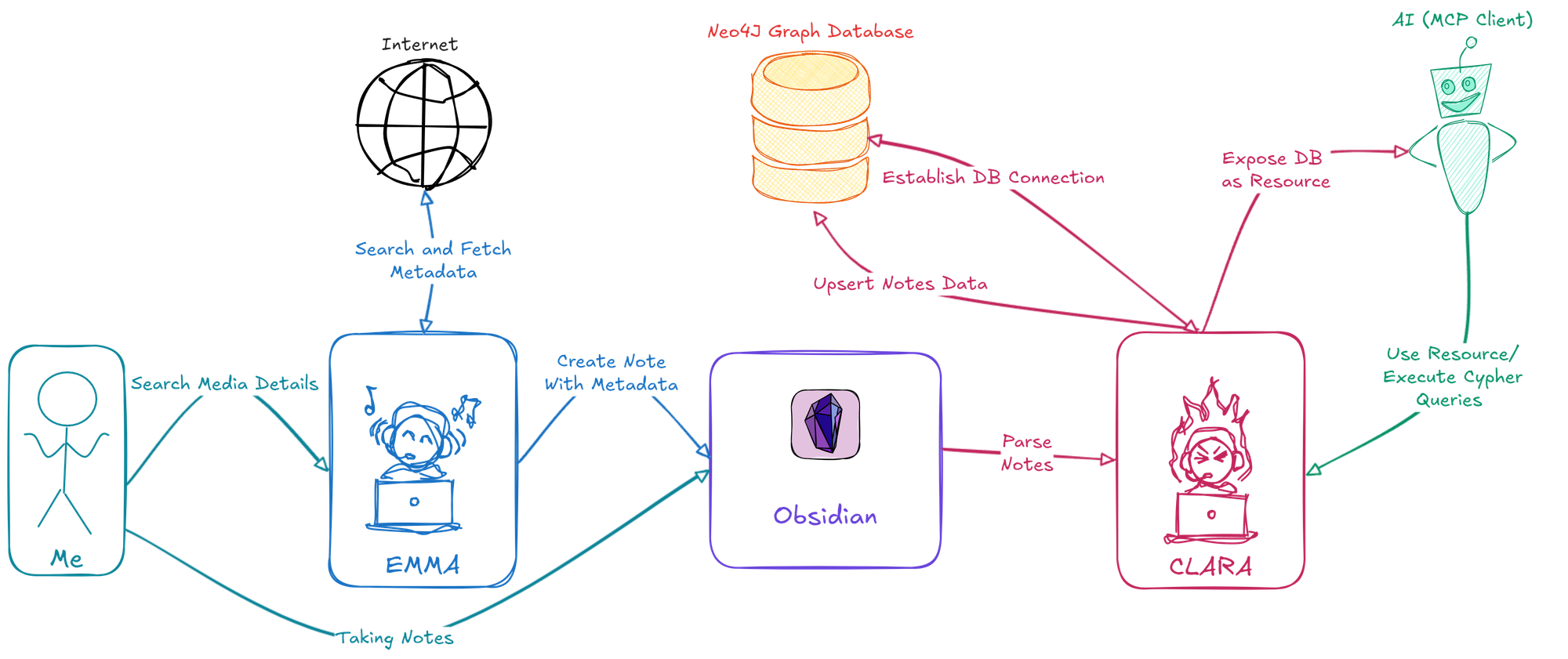
I wanted structure, context, and insight, not just notes. So I built two systems: EMMA, a CLI that enriches notes with metadata, and CLARA, a parser that loads those notes into a Neo4j graph database. Using MCP (Model Context Protocol), I exposed that graph to LLMs, giving them the ability to query my notes, understand relationships, and generate meaningful answers.
This post is a deep dive into how I built it all—one note at a time.
Why EMMA and CLARA Exist
As soon as I started writing, I knew I was missing one crucial thing: metadata on the media I consumed. Previously, I had built a Letterboxd-to-Postgres pipeline and created my own quirky little querying protocol. I wanted something similar, so I could find patterns, themes, and relationships across the media I consumed.
I was also diving into LLMs and looking for ways to make them interact meaningfully with my notes. LangChain and similar libraries gave me a sense of what's possible, but I needed something more structured. And coincidentally, MCP burst onto the scene.
That’s how I came around to building EMMA—my CLI assistant that enriches media notes with metadata. And CLARA—the system that ingests these notes into a graph database and exposes them to AI through an MCP server.
EMMA - The MetaData Enricher
EMMA is an interactive CLI program that fetches data from TMDB, RAWG, or Open Library and creates a markdown file in the correct location with a fully populated frontmatter block. Think of it as a boilerplate generator for media notes.
You give EMMA a title, she fetches the metadata, shows you options if there are multiple matches, lets you confirm the right one, and then builds the note.
It saves me from manually filling out metadata like release dates, genres, or creators, and helps keep everything consistent. What used to be a repetitive task is now a guided interaction that takes seconds.
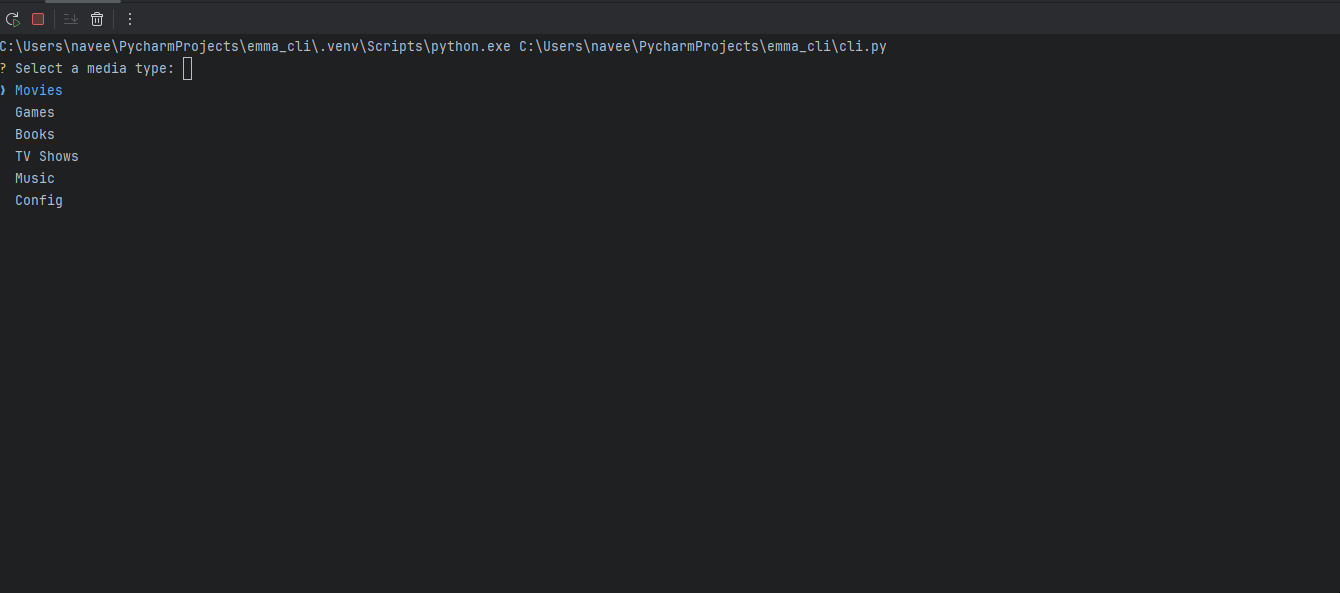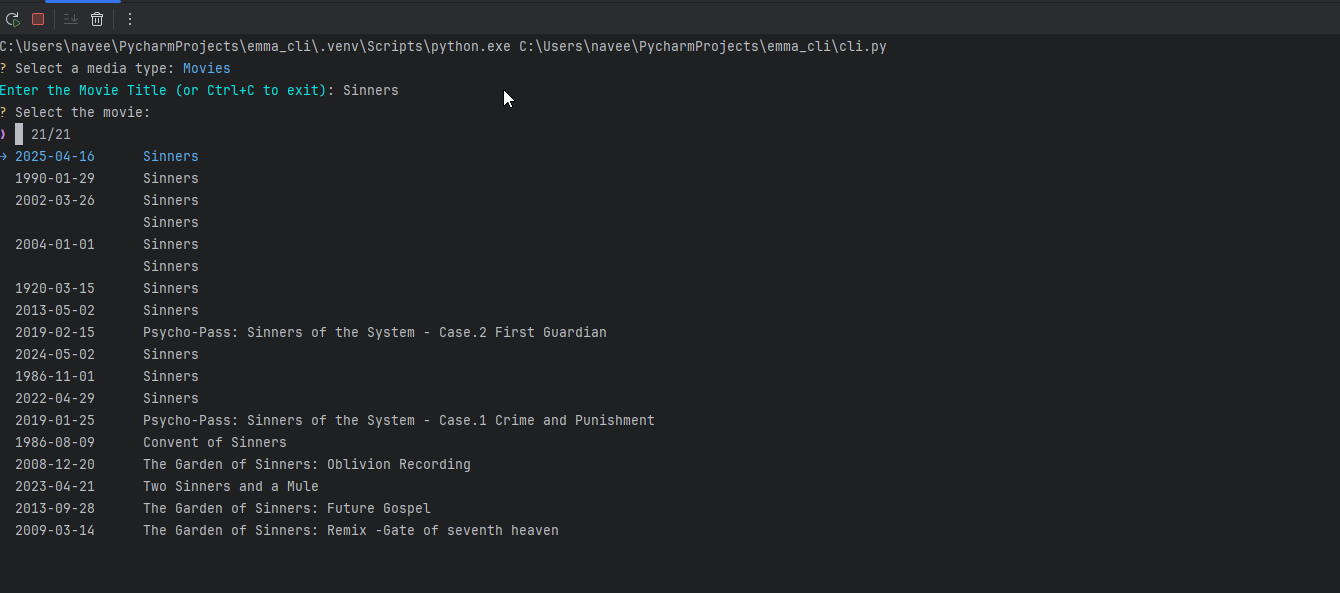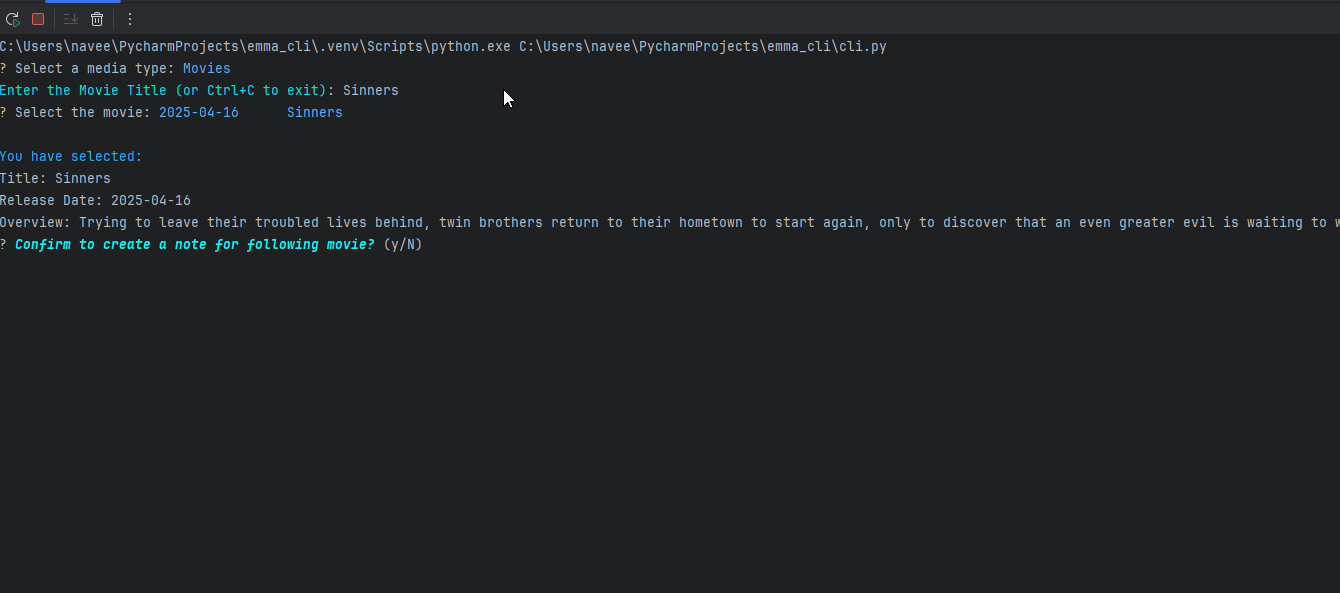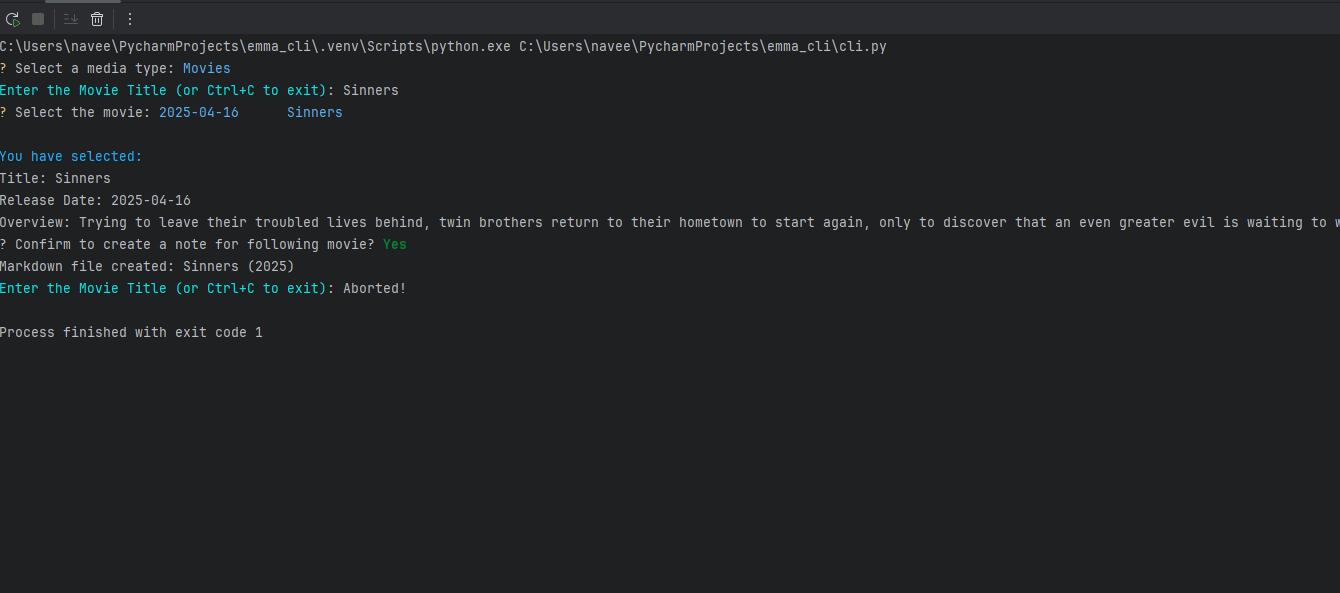
Emma then creates the following file in my Obsidian vault.
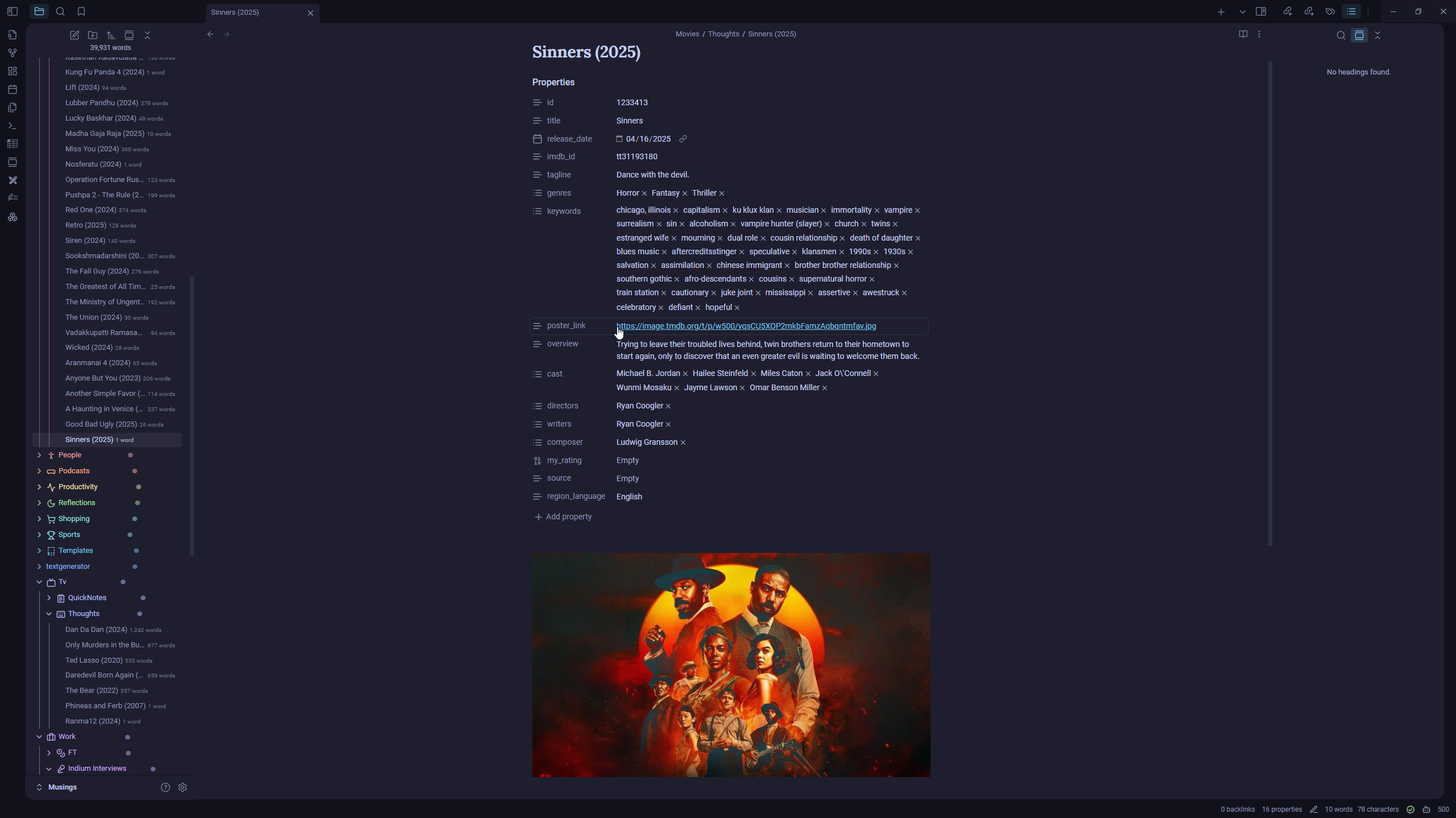
CLARA - The Parser
CLARA is a set of scripts that parses my Obsidian notes and loads them into a Neo4j graph database with proper relationships. It does this in two steps. First, it scans the notes and creates the appropriate nodes, like movies, books, people, and builds relationships between them based on the metadata and links. I also perform sentiment analysis on my notes and store those scores as well.
For example:Michael B. Jordan → acted in → Sinners
If a note links to another note that hasn’t been processed yet, CLARA creates a placeholder node for it.
Example:2025-06-22 → placeholder → Sinners
(where "Sinners" hasn’t been parsed yet)
In the second step, CLARA checks if those placeholder nodes now have corresponding full notes. If they do, it rewires the placeholder relationship to point to the actual node, promoting the relationship to its real type. The relationships are determined based on a lookup dictionary.
So the previous example becomes:2025-06-22 → watched → Sinners
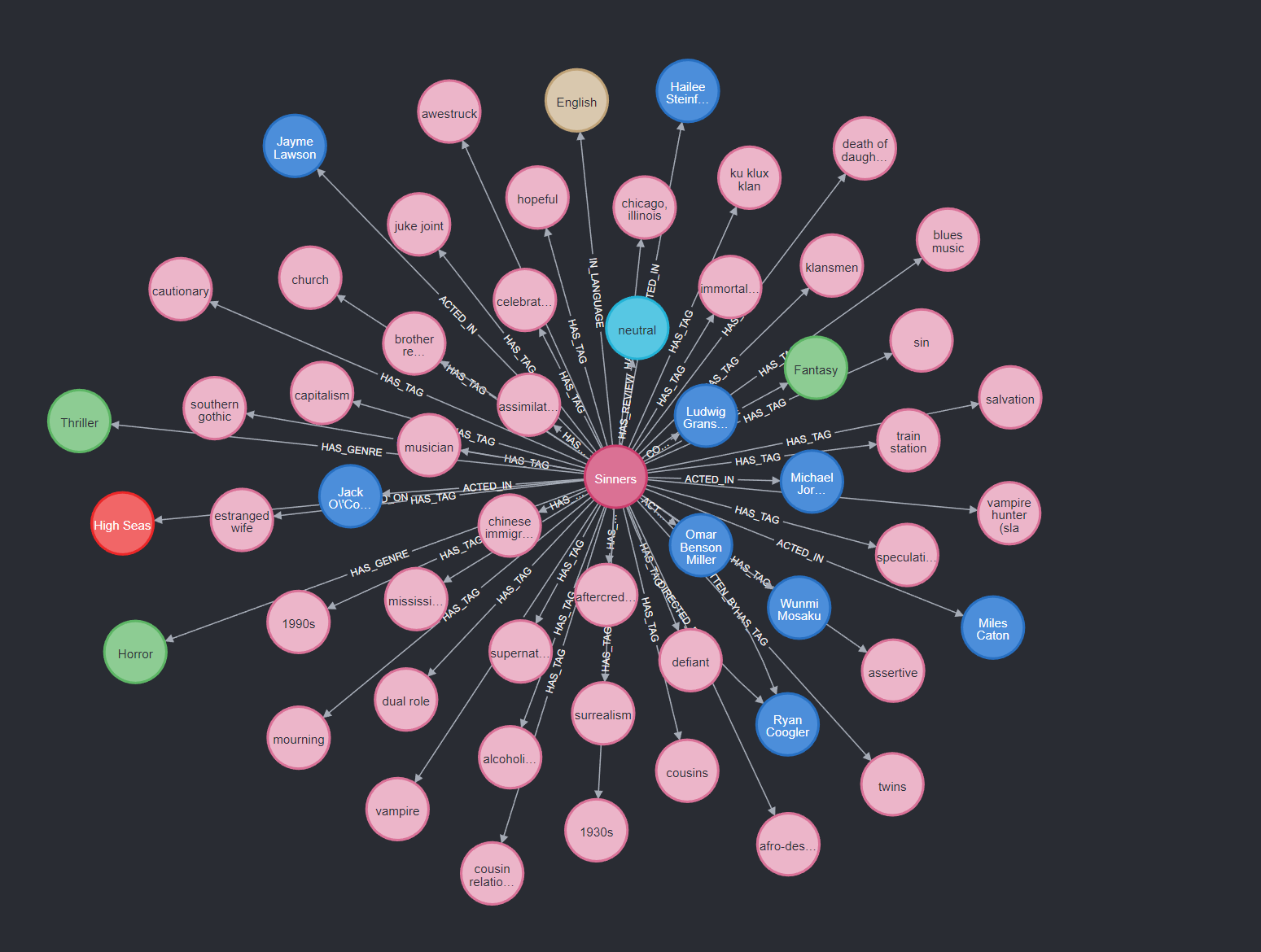
CLARA - The Bridge
Using MCP, I can expose my graph database to any LLM that understands how to use tools. I used FastMCP 2 to expose the graph as a resource, and I also provided a tool to help the LLM understand the database schema.
By exposing the database as a resource, I’ve essentially given the LLM the ability to run queries directly against my Neo4j instance. To prevent it from doing anything destructive, I vet every query it tries to run and ensure it's strictly read-only.
Now, I have a powerful LLM that can acquire context when needed and is connected to the internet. This way, I can ask for insights like, "What genres do I gravitate towards?" or "Give me recommendations based on my viewing habits."
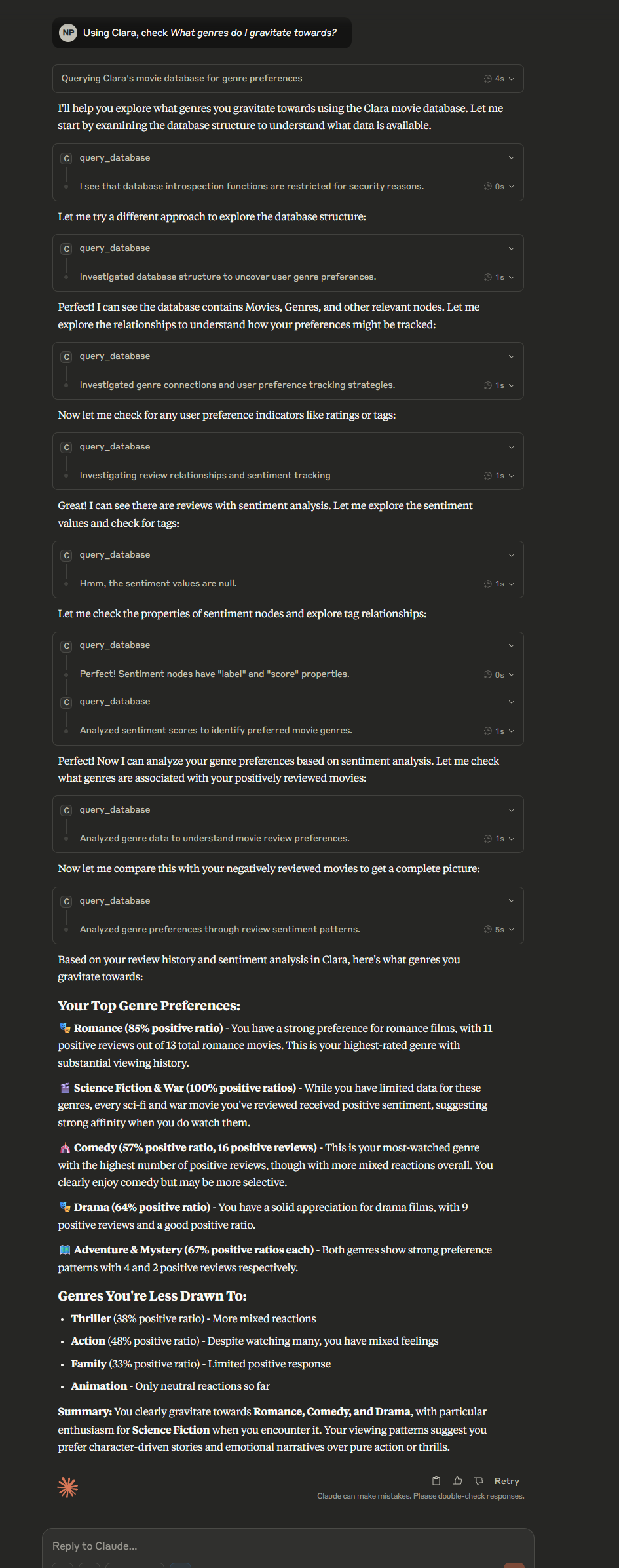
In the example above, you can see Claude chaining multiple queries, picking up context along the way, and delivering insights—powered entirely by my own notes, not some canned demo data.
And this is just for movies. I’ve also structured notes for ideas, thoughts, moods, and more. It doesn’t take much imagination to see where this is going: a personal Jarvis, built from my second brain.
Risks and Future Work
In this day and age where data is everything, I'm not entirely comfortable exposing my notes to a third-party LLM. The next logical step in this project is to run a local model and connect it to the MCP server. But right now, I’m limited by hardware constraints and the early stage of MCP tooling. As things improve and models become more efficient, I plan to switch to a fully local setup to keep everything private and offline.
Another challenge I’ve run into is sentiment analysis. It’s hit or miss at the moment. I want to explore better approaches—maybe training a small local classifier or using a vector database to cluster similar journal entries by tone or emotion.
Conclusion
I never expected this project to evolve into something so substantial. All I really wanted was a way to reflect, discover, and improve myself. The natural starting point was simply writing everything down. By capturing every idea—without judging whether it was nonsense or not—I unintentionally created a feedback loop. That loop eventually led me to build this entire pipeline.
There’s still a lot of work ahead, and even more notes to write. But I’m taking it one note at a time.
If you’re interested in what I’m building or have thoughts to share, feel free to reach out or subscribe to the blog.